Sign in to see all reviews and comparisons. It's Free!
By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH
Privacy Policy
and agree to the
Terms of Use.
Orange is an open source data visualization and analysis tool, where data mining is done through visual programming or Python scripting. The tool has components for machine learning, add-ons for bioinformatics and text mining and it is packed with features for data analytics.
Category
Data Mining Software
Features
• Open Source
• Interactive Data Visualization
• Visual Programming
• Supports Hands-on Training and Visual Illustrations
• Add-ons Extend Functionality
License
Open Source Software
Price
Free
Pricing
Subscription
Free Trial
Available
Users Size
Small (<50 employees), Medium (50 to 1000 employees), Enterprise (>1001 employees)
• Open Source
• Interactive Data Visualization
• Visual Programming
• Supports Hands-on Training and Visual Illustrations
• Add-ons Extend Functionality
What are the benefits?
•For everyone- beginners and professionals
•Execute simple and complex data analysis
•Create beautiful and interesting graphics
•Use in a data analysis lecture
•Access external functions for advanced analysis
Decide Rating™
Editor Rating
Aggregated User Rating
Rate Here
Ease of use
9.6
7.4
Features & Functionality
9.5
8.1
Advanced Features
9.5
8.4
Integration
9.4
8.4
Performance
9.4
8.4
Customer Support
9.6
7.5
Implementation
8.6
Renew & Recommend
7.5
Bottom Line
Orange is an open source data visualization and analysis tool, where data mining is done through visual programming or Python scripting. The tool has components for machine learning, add-ons for bioinformatics and text mining and it is packed with features for data analytics.
9.5
Editor Rating
8.1
Aggregated User Rating
172 ratings
You have rated this
Orange is an open source data visualization and analysis tool. Orange is developed at the Bioinformatics Laboratory at the Faculty of Computer and Information Science, University of Ljubljana, Slovenia, along with open source community. Data mining is done through visual programming or Python scripting.
The tool has components for machine learning, add-ons for bioinformatics and text mining and it is packed with features for data analytics. Orange is a Python library. Python scripts can run in a terminal window, integrated environments like PyCharm and PythonWin, or shells like iPython.
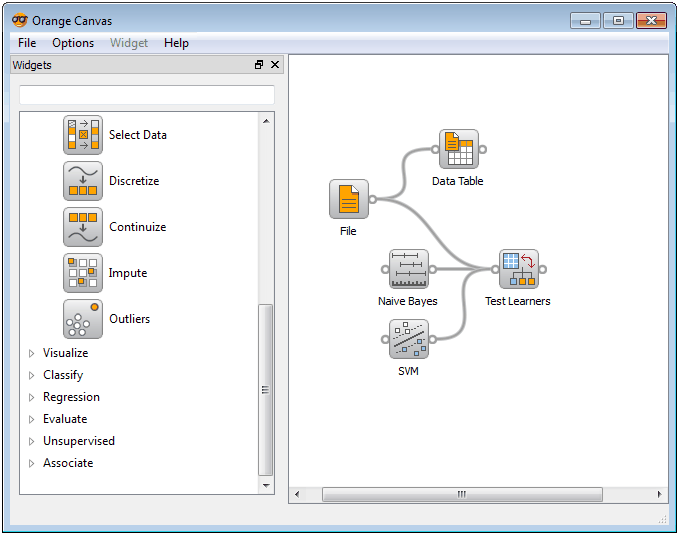
Orange consists of a canvas interface onto which the user places widgets and creates a data analysis workflow. Widgets offer basic functionalities such as reading the data, showing a data table, selecting features, training predictors, comparing learning algorithms, visualizing data elements, etc. The user can interactively explore visualizations or feed the selected subset into other widgets.
Orange Data mining
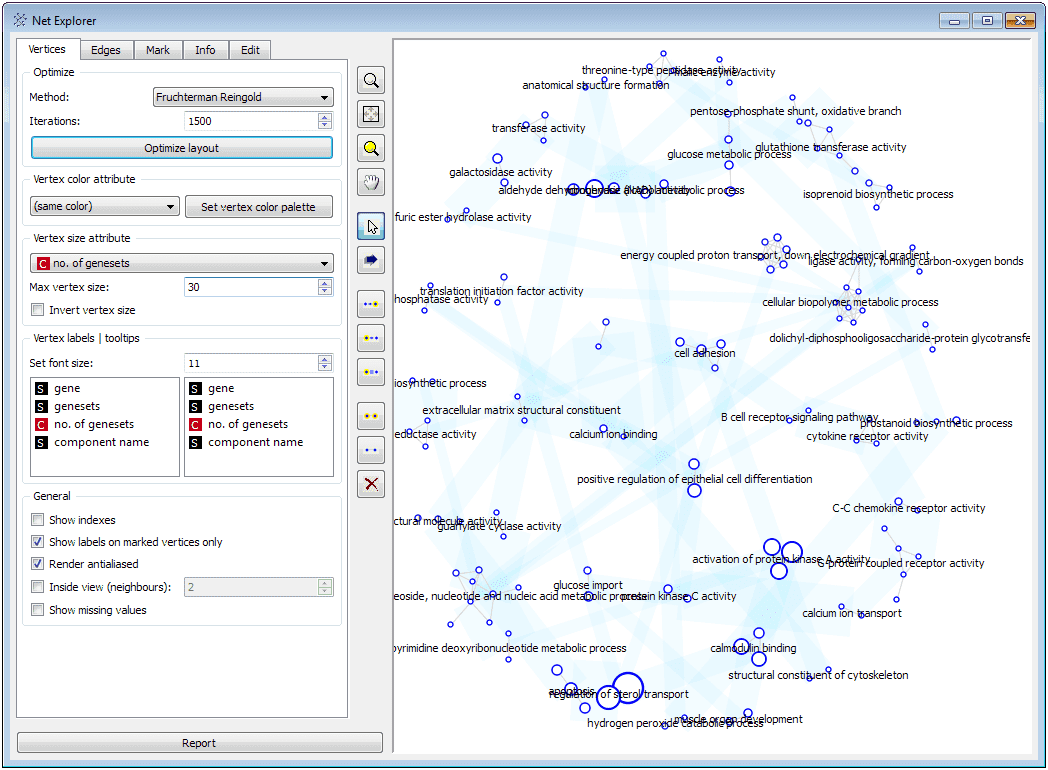
Orange-Visualization of interactions of genetic pathways
In Orange, data analysis process can be designed through visual programming. Orange remembers the choices, suggests most frequently used combinations. Orange has features for different visualizations, such as scatterplots, bar charts, trees, to dendrograms, networks and heatmaps. By combining the various widgets the design of data analytics framework can be done. There are over 100 widgets with coverage of most of standard data analysis tasks and specialized add-ons for Bioorange for bioinformatics.
Orange- Tree view of Orange widgets
Own widgets, can be developed and the scripting interface can be extended to create self contained add-ons, integrating with the rest of Orange, allowing components and code reuse. Orange runs on Windows, Mac OS X, and variety of Linux operating systems.
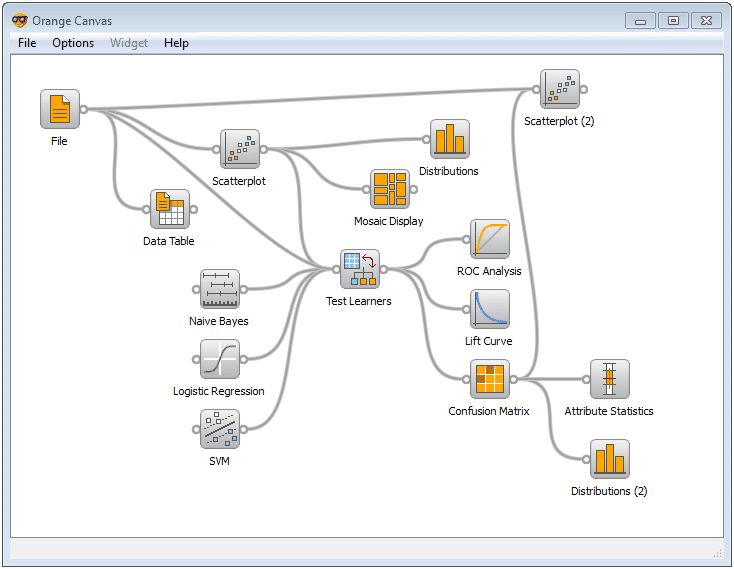
Orange-Data exploration by construction of analysis schema
Orange comes with mutliple classification and regression algorithms. New ones can be build or there are features to wrap existing learners and add some preprocessing to construct new variants.
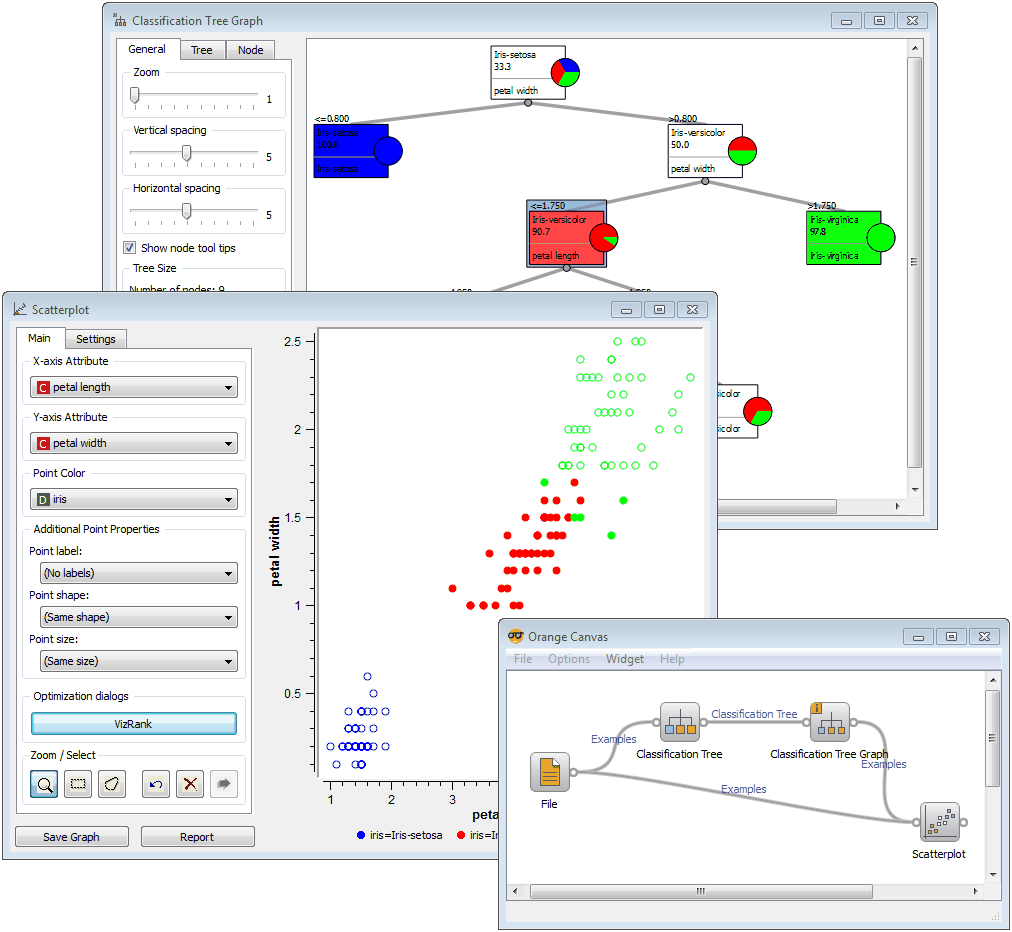
Orange-Explorative analysis and classification trees
Orange can read files in native and other data formats. Orange is devoted to machine learning methods for classification, or supervised data mining. Classification uses two types of objects: learners and classifiers. Learners consider class-labeled data and return a classifier. Regression methods in Orange are very similar to classification. Both intended for supervised data mining, they require class-labeled data.
Learning of ensembles combines the predictions of separate models to gain in accuracy. The models may come from different training data samples, or may use different learners on the same data sets. Learners may also be diversified by changing their parameter sets. In Orange, ensembles are simply wrappers around learners. They behave just like any other learner. Given the data, they return models that can predict the outcome for any data instance.
It can also be used to test new machine learning algorithms. Orange is valuable in the classroom as it can be utilized in the teaching of machine learning and data mining .
Company size
Medium (50 to 1000)
User Role
Super User
User Industry
Financial services
Rating
Ease of use8.6
Features & Functionality8.2
Orange is an open-source software package supported on MacOS, Windows and Linux Operating systems and serves as a platform for experiment selection, sytems of recommendation as well as predictive modelling.
Advanced Features8.3
Orange also has add-ons for specialist tasks such as fusing data sets, teaching machine learning concepts, analysis of geospatial data, bioinformatics, image analysis, network analysis, time series analysis, natural language processing and text mining.
Integration8.1
Performance8.5
Training 8.2
Customer Support8.3
Implementation8.1
Renew & Recommend8.2
ADDITIONAL INFORMATION Built-in functionalities are numerous. Some of them include: reading of data, input of data into data tables, selection of feature, training predictors, comparing different learning algorithms, and visualization of data elements. The Orange software contains widgets for data input, widgets for common visualization which produce very interactive graphics, widgets for classification, widgets for regression, widgets for evaluation and those for other complex analytical functions.











Complex analytical functions
It can also be used to test new machine learning algorithms. Orange is valuable in the classroom as it can be utilized in the teaching of machine learning and data mining .
Medium (50 to 1000)
Super User
Financial services
Orange is an open-source software package supported on MacOS, Windows and Linux Operating systems and serves as a platform for experiment selection, sytems of recommendation as well as predictive modelling.
Orange also has add-ons for specialist tasks such as fusing data sets, teaching machine learning concepts, analysis of geospatial data, bioinformatics, image analysis, network analysis, time series analysis, natural language processing and text mining.
ADDITIONAL INFORMATION
Built-in functionalities are numerous. Some of them include: reading of data, input of data into data tables, selection of feature, training predictors, comparing different learning algorithms, and visualization of data elements. The Orange software contains widgets for data input, widgets for common visualization which produce very interactive graphics, widgets for classification, widgets for regression, widgets for evaluation and those for other complex analytical functions.
Orange hits the Data Mining Sweet Spot
Ease of use and tutorials are best
Get answers relatively quickly
Medium (50 to 1000)
End User
Computer
Orange is easy to use and right off. If you have tried KNIME or RapidMiner, Orange will feel familiar, but easier to get started.
Great functionality for classifications, clustering, forecasts and other predictive modeling.
Add-ons for text, networking, geo, and bioinformatics. Standard neural, gradient descent, Ada Boost.
Integrates well with Python scripts. Useful with Excel, CSV, other data types. SQL interface needs to be simplified
Performance is as expected and dependent on underlying hardware
Excellent basic tutorial videos on youtube. Great example workflows and data sets.
Lacking support outside of documentation and tutorials. They really need a good user forum.
Need better documentation on deployment with python scripts.
Will definitely continue to use and recommend
ADDITIONAL INFORMATION
KNIME, RapidMiner