Sign in to see all reviews and comparisons. It's Free!
By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.
Bigdata
Now Reading
Trifacta Data Transformation Platform to remove Data Analysis Bottleneck
Trifacta Data Transformation Platform to remove Data Analysis Bottleneck
Trifacta Data Transformation Platform to remove Data Analysis Bottleneck : Trifacta Data Transformation Platform, uses visualization, machine learning methods and Predictive Interaction technology to remove a critical bottleneck in the Big Data stack turning raw data into a usable form. Currently, data scientists, IT programmers, and business analysts must work through the time consuming challenge of transforming raw data into workable inputs for their analytic tools. Data scientists spend as much as 60 to 80 percent of their time just transforming data rather than focusing on finding insights. This human bottleneck is hindering the ability of enterprises to extract value from data.
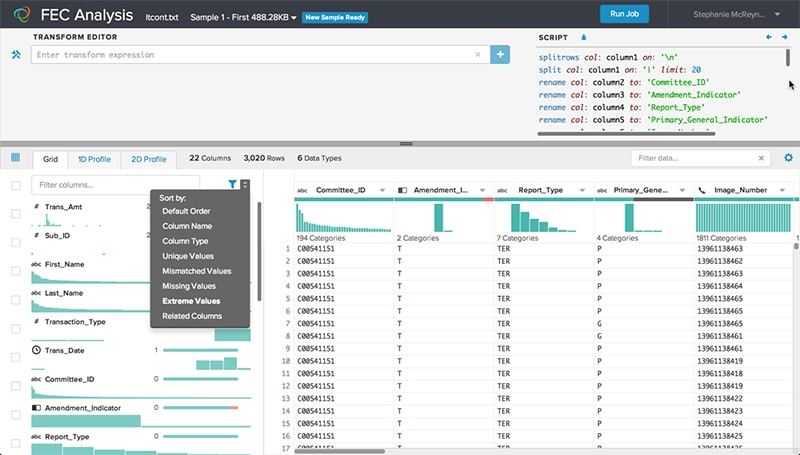
Trifacta’s Data Transformation Platform uses Predictive Interaction technology to elevate data manipulation into a visual experience, allowing users to quickly and easily identify features of interest or concern. Trifacta’s predictive algorithms observe both user behaviour and properties of the data to anticipate the user’s intent and make suggestions without the need for user specification. As a result, data transformation becomes a lightweight experience that is far more agile and efficient than traditional coding or manual manipulation.
Trifacta takes an agile, visual approach to data transformation providing the user with continuous visual feedback on how the shape and content of a dataset is affected when different transforms are applied. Trifacta, enhances the value of an enterprise’s Big Data by enabling users to easily transform raw, complex data into clean and structured formats for analysis.
Trifacta Data Transformation Platform users can process data of any volume. Users can scale their data transformations from immediate execution on small data through interactive execution on medium sized data, all the way to execution of terabytes to petabytes. The Trifacta platform addresses the complete range of processing use cases available on Hadoop.
Trifacta advanced visual data profiling capabilities guide users through a deep understanding of the characteristics of any data set and provides native support for more complex data formats, including JSON, Avro, ORC and Parquet. The platform leverages the multi workload processing features of Hadoop to scale data transformation processing seamlessly from small to big data through native use of both Spark and MapReduce.
Trifacta uses a combination of machine learning and interactive data visualization techniques to automatically evaluate the distribution and statistical relevance of data and provide analysts with immediate visibility into unique elements of the data set like data distributions, gaps in data collection, and unusual skew of the data. The Trifacta release removes the bottleneck for the analyst of parsing Hadoop specific data storage formats, by automating the interpretation of these formats.
Trifacta’s ability to ingest, transform and write back out JSON, Avro, ORC and Parquet data means that Trifacta transformed data is immediately accessible through a wide variety of Hadoop’s SQL-access frameworks, including Stinger, Apache Drill and Impala.
Trifacta seamlessly optimizes data transformation processing for data of any size. Trifacta’s domain-specific language (DSL) architecture seamlessly and automatically matches the size of the data for transformation with the data processing engine best suited for the workload. Customers are not required to understand high level languages like PIG or Scala, or choose between Hadoop execution frameworks like Spark or MapReduce. Using the Trifacta DSL, called Wrangle, transformation logic is defined once and then automatically translated into native code for the Hadoop processing framework best suited for the data set being transformed.










By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.