
Big data Analytics and Predictive Analytics

Gartner added big data to its 2011 hype cycle and has called it one of the top 10 strategic technologies for 2012, stating, “The size, complexity of formats and speed of delivery exceeds the capabilities of traditional data management technologies; it requires the use of new or exotic technologies simply to manage the volume alone".Big data has few key characteristics such as volume, sources, velocity, variety and veracity.
Big data Analytics and Predictive Analytics
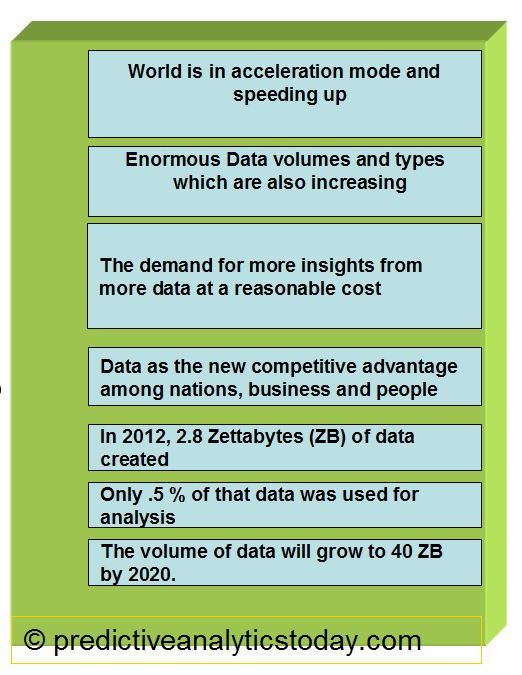
Data is emerging as the world’s newest resource for competitive advantage among nations, organizations and business. It is estimated that every day we create 2.5 quintillion bytes of data from a variety of sources. These are from the computer notes to posts on social media sites and from purchase transaction records to pictures.
Data in Big data and Predictive Analysis
These collection of data sets which are so large and complex and are difficult to process using the on hand database management tools are known as Big data. The challenges in Big data includes capture, curation, storage, search, sharing, transfer, analysis and visualization of the data.
Big data has few key characteristics such as volume, sources, velocity, variety and veracity. The first among these is volume. Experts predict that by 2020, the volume of data in the world will grow to 40 Zettabytes. This affects every business, governments and individual. Based on a recent study,2.8 Zettabytes of data were created in 2012 and only .5% of that data were used for analysis. Unstructured data, such as texts, notes, logs makes up a large chunk of this data volume and these requires text mining to analyze the data.
The business data is also growing at these same exponential rate too.Along with the volume, the number of sources, from where the data is extracted are also growing. Data is increasingly accelerating the velocity at which it is created, as the process are moved from batch to a real time business. The demands of the business from these data also has increased, from an answer next week to an answer in a minute.
Bigdata Platforms and Bigdata Analytics Software
Big data Analytics
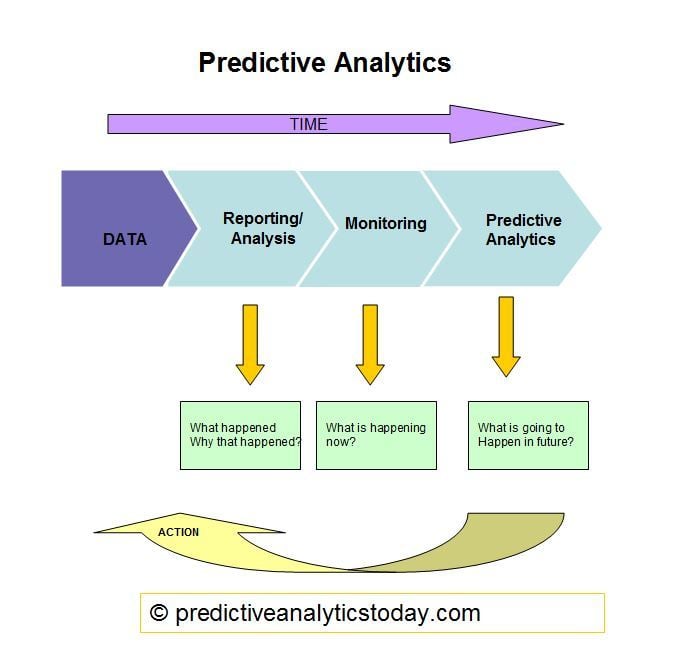
Business intelligence (BI) provides OLAP based, standard business reports, ad hoc reports on past data. These ad hoc analysis looks at the static past of data. This has its purpose and business uses, but doesnot meet the needs of a forward looking business. Forward looking big data analytics requires statistical analysis, statistical forecasting, casual analysis, optimization, predictive modeling and text mining on the large chunk of data available. There are performance issues, when these high volume past data are used in the relational data model, for a forward looking big data analytics, for future in the current system landscape in many organizations.
Predictive Analytics Value Chain
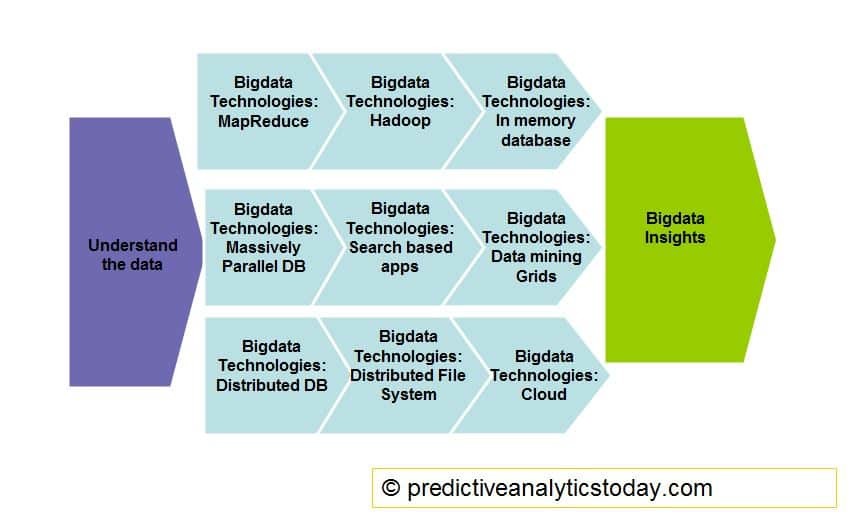
Big Data Analytics will help organizations in providing an overview of the drivers of their business by introducing big data technology into the organization. This is the application of advanced analytic techniques to a very large data sets. These can not be achieved by standard data warehousing applications. These technologies are hadoop, mapreduce, massively parallel processing databases, in memory database, search based applications, data-mining grids, distributed file systems, distributed databases, cloud etc.
The Technology drivers for Big data Analytics
• Multi core processors
• Lower power consumption
• Low cost storage
• High speed local networking
Big data Technology
With the Big data analytics the relevant information from data warehouse in terabytes, petabytes and exabytes can be extracted and analyzed to transform the business decisions for the future.
The reason that big data is currently a hot topic is partly due to the fact that the technology -MapReduce, Hadoop, In memory database, Massively parallel processing database, database grids, search based functionality etc are now available to process these large data sets which are mostly a combination of structured and unstructured data. With these technologies, it is now possible to bring insights from these data in to the day to day decision making process.
Big data Analytics Technology
1.MapReduce
MapReduce was created by Google in 2004. It is a model inspired by the map and reduce functions for processing large data sets with a parallel, distributed algorithm on a cluster.
2.Hadoop
Hadoop is an open source Apache implementation project. It was created by Yahoo in 2004 as a way to implement the MapReduce function. Hadoop enables applications to work with huge amounts of data stored on various servers. Hadoop has a large scale file system which is known as Hadoop Distributed File System or HDFS and this can write programs, manages the distribution of programs, accepts the results, and then generates a data result set.
3.In memory database
Data in main memory can be accessed faster than data stored in hard disk or other flash storage device. A database management system that primarily relies on main memory for computer data storage is called an In memory database.
4.Massively parallel processing databases
Massively parallel processing is a loosely coupled databases where each server or node have memory or processors to process data locally and data is partitioned across multiple servers or nodes.
5.Search based applications
Search based applications are search engine platform is used to aggregate and classify data and use natural language technologies for accessing the data.
6.Data mining grids
Data mining grids are environment which uses grid computing concepts, which allows to integrate data from various online and remote data sources.
7.Distributed file systems
Distributed file system is a shared file system which is shared by being simultaneously mounted on multiple servers.
8.Distributed databases
Distributed databases is a database system which is controlled by a distributed database management system.
9.Cloud
Cloud computing is distributed computing over a network.
10.NewSQL Database
NewSQL relational database management systems provide the same scalable performance for OLTP – online transaction processing read-write workloads.
11.Graph Database
Graph database is based on graph theory, uses nodes, properties, and edges and provides index-free adjacency.
12.SQL and No SQL Cloud database
SQL and No SQL Cloud database runs on a cloud computing platform.
You may like to review the following Bigdata articles :
Bigdata Platforms and Bigdata Analytics Software
Data preparation tools and platforms
Business benefits of Big data Analytics
- March towards business goals faster by turning dormant data into new opportunities making use of big data analytics.
- Intuitively design very complex predictive models using casual factors
- Big Data integration capabilities with traditional databases and other systems.
- Hadoop Distributed File System for faster ‘reading from’ and ‘loading to’ performance and scalability.
- Wide range of Big data applications and analytics to analyse more history data.
- Visualize, discover, and share hidden insights for forward looking plan.
- From adhoc report analysis to Real-time answers using Big data.
- Linguistic analysis and extracts relevant content from files, Web logs and social media.
- Data from Multiple sources analysed for one business solution.
- Real time answers from unstructred data.
Big data Analytics and Predictive Analytics
Big data and Predictive Analytics processing
Predictive Analytics identifies meaningful patters of Big data to predict future events and assess the attractiveness of various options. Predictive analytics can be applied to any type of unknown data, whether it be in the past, present or future.Predictive Analytics provides the Business Intelligence about the future using the insights of Big data.
Predictive Analytics Examples
Some of the examples where Predictive Analytic can be used on Big data are :
- Provide Alert when market share for my products are dropping in specific regions.
- Where and what was the Rx trend and what predictions are there for future ?
- Which products and product groups are our best and worst? Used By Which regions? and what is the percentage cummulative decline ?
- How much commission did the sales folks accumulate ?
- What are a few planned scenarios moving forward ?
- How do I leverage the past to segment regions to concentrate to reduce the drop moving forward?
- Based on previous Rx, what clusters of regions should I market to?
- What’s the word on the street? How will the digital media help me target new regions and what is going to be my marketing effectiveness ?
You may also like to read, Predictive Analytics Free Software, Top Predictive Analytics Software, Predictive Analytics Software API, Top Free Data Mining Software, Top Data Mining Software,and Data Ingestion Tools.
Top Predictive Lead Scoring Software, Top Artificial Intelligence Platforms, Top Predictive Pricing Platforms,and Top Artificial Neural Network Software, and Customer Churn, Renew, Upsell, Cross Sell Software Tools
More Information on Predictive Analysis Process
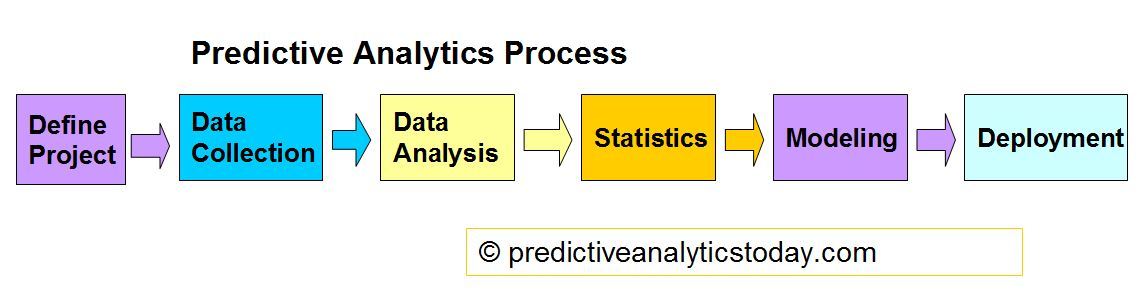
Predictive Analytics Process Flow
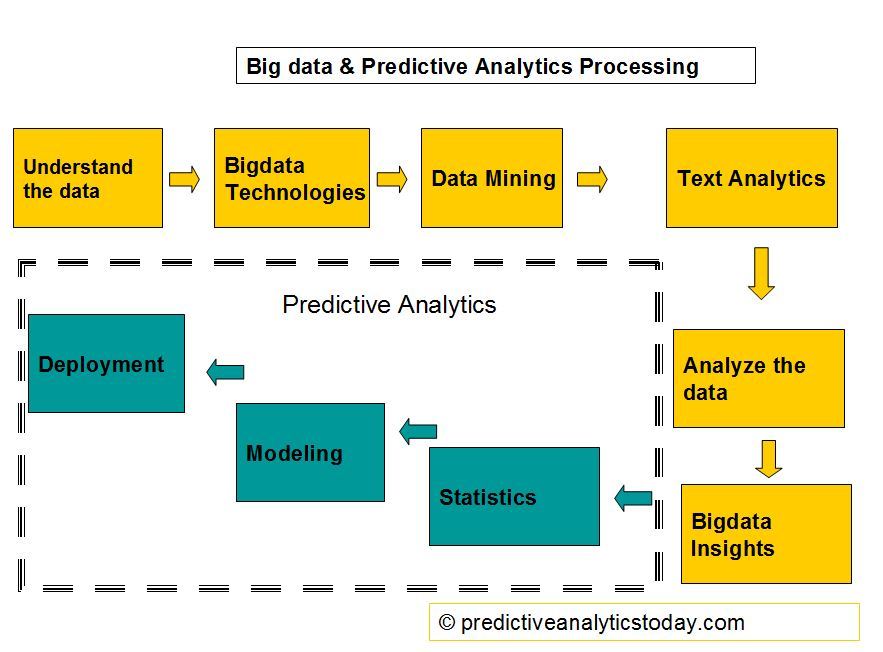
For more information of predictive analytics process, please review the overview of each components in the predictive analytics process: data collection (data mining), data analysis, statistical analysis, predictive modeling and predictive model deployment.
What are Big data Analytics?
Big Data Analytics will help organizations in providing an overview of the drivers of their business by introducing big data technology into the organization. This is the application of advanced analytic techniques to a very large data sets. These can not be achieved by standard data warehousing applications. These technologies are hadoop, mapreduce, massively parallel processing databases, in memory database, search based applications, data-mining grids, distributed file systems, distributed databases, cloud etc.
What is Big data Technology?
With the Big data analytics the relevant information from data warehouse in terabytes, petabytes and exabytes can be extracted and analyzed to transform the business decisions for the future. The reason that big data is currently a hot topic is partly due to the fact that the technology -MapReduce, Hadoop, In memory database, Massively parallel processing database, database grids, search based functionality etc are now available to process these large data sets which are mostly a combination of structured and unstructured data.
What are the business benefits of Big data Analytics?
The business benefits of Big Data Analytics include turn dormant data into new opportunities making use of big data analytics, intuitively design very complex predictive models using casual factors, Big Data integration capabilities with traditional databases and other systems, Hadoop Distributed File System , wide range of Big data applications and analytics to analyse more history data and many more.
What is Predictive Analytics?
Predictive Analytics identifies meaningful patters of Big data to predict future events and assess the attractiveness of various options. Predictive analytics can be applied to any type of unknown data, whether it be in the past, present or future.Predictive Analytics provides the Business Intelligence about the future using the insights of Big data.





?")




ADDITIONAL INFORMATION
This was a very interesting read.
I would like to see more on this topic.
ADDITIONAL INFORMATION
I too think this was interesting reading; it covered many of the salient points of Big Data Analytics. There are a couple of items, I respectfully submit that the author did not address [although they may be addressed in the links provided,] and which I’d like to see addressed at some point. To wit:
§ There is not any space allotted in the literature to address the management requirements of hyper-large clusters, and from what I’ve read; I don’t see vendors offering any products that speak to the point. Specifically; in a Hadoop cluster [for example] with perhaps 100s of nodes; what is the impact on management of that cluster’s processing capacity and operations staff? Likewise, with a large enough cluster, one can reasonably expect to have a downed node almost consistently. Thus far, no vender that I’ve researched, except perhaps one, offers a single system image and automatically accounts for recovery from downed nodes at the OS layer. Moreover the expectation is that fail-over processing in reaction to a failed node condition will undoubtedly burden the cluster with the additional processing burden on the cluster if that processing is not done at the OS layer. What then happens to expected performance expectations [or agreements.]
§ None of the vendors claiming to be in the Big Data space are taking on the problem of zero [or very low] data latency. Gartner, I believe, published a report on Zero Latency Enterprises [ZLE] in a paper a number of years ago, but no one today save for SAP, and they vaguely refer to ZLE, has taken on the requirement of ZLE or very low latency [VLLE.] It does an enterprise little good to claim predictive analysis and real-time monitoring capabilities via a DW unless the ZLE issue is tackled head on. I’d like to see the authors [Gartner, perhaps] reintroduce this requirement as it applies to Big Data Predictive Analytics.
§ As regards to in-memory data bases, it does a DW owner little good to have an in-memory data base if that owner is always looking at stale information. A few examples come to mind: capturing a customer before they’ve left the store in retail; real time fraud detection in credit card processing as offered in a comForte paper by comparing card transactions with something seemingly as insignificant as a Tweet.
§ I expect that ZLE will become part of the price of entry into the arena as data volumes continue to grow. To perform an ETL activity off-line in a batch or parallel batch mode won’t cut the mustard until someone figures out how to get more than 24 hours into a day. DW/BI vendors have to start offering or, at least, showing on their product road maps how they address the issue of ZLE or VLLE in an interoperable, heterogeneous environment.
ADDITIONAL INFORMATION
Fantastic