Sign in to see all reviews and comparisons. It's Free!
By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH
Privacy Policy
and agree to the
Terms of Use.
What is Data Mining ? Data Mining is the computational process of discovering patterns, trends and behaviors, in large data sets using artificial intelligence, machine learning, statistics, and database systems. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use. Data mining is considered as a synonym for another popularly used term, known as KDD, knowledge discovery in databases. Data mining is an essential step in the process of predictive analytics. The process of mining and extraction of useful information from the existing data is an interdisciplinary work involving mathematicians, statisticians, computer programmers.
Data Mining
Data Mining Definition
The proper use of the term data mining is data discovery. But the term is used commonly for collection, extraction, warehousing, analysis, statistics, artificial intelligence, machine learning, and business intelligence. Statistics provide sufficient tools for data analysis and machine learning deals with the different learning methodologies. Before a data can be mined it needs to be cleaned. This removes the errors and ensures consistency. Data mining methods are generalization, characterization, classification, clustering, association, evolution, pattern matching, data visualization, and meta rule guided mining.
The knowledge discovery in databases is defined in various different themes.
Data Mining Definition- Simplified
(1) pre processing, (2) data mining, and (3) results validation.
Data Mining Definition- Simplified
Knowledge Discovery in Databases (KDD) process definition:
(1) Selection
(2) Pre processing
(3) Transformation
(4) Data Mining
(5) Interpretation/Evaluation.
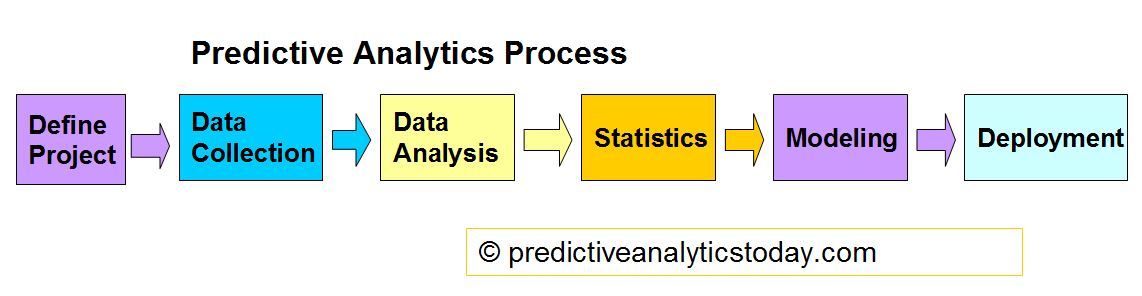
Cross Industry Standard Process for Data Mining (CRISP-DM) definition:
(1) Business Understanding
(2) Data Understanding
(3) Data Preparation
(4) Modeling
(5) Evaluation
(6) Deployment
Data Mining Overall Plan
SAS Institute overall plan for data mining is known as SEMMA. This plan has 5 steps which are as follows: sample, explore, modify, model, and assess.
Step 1: Sample
Extract a portion of a large data set big enough to contain the significant information yet small enough to manipulate quickly.
Step 2: Explore
Search speculatively for unanticipated trends and anomalies so as to gain understanding and ideas.
Data Mining Overall Plan
Step 3: Modify
Create, select, and transform the variables to focus the model construction process.
Step 4: Model
Search automatically for a variable combination that reliably predicts a desired outcome.
Step 5: Assess
Evaluate the usefulness and reliability of findings from the data mining process.
Tasks in Data Mining
The tasks in data mining are either automatic or semi automatic analysis of large volume of data which are extracted to check for previously unknown interesting patterns. These are cluster analysis, anomaly detection on unusual records and dependencies check using the association rule mining. This usually involves using database techniques such as spatial indices. These patterns thus identified provides a summary of the input data, and can used in further analysis or in machine language and predictive analytics. The use of data mining methods for samples of data are known as data dredging, data fishing, and data snooping .Mining techniques are employed in different kinds of databases, including relational, transaction, object-oriented, spatial, and active databases.
Data mining involves six common classes of tasks:
1.Anomaly detection- This is the Outlier or deviation detection, where the identification of unusual data records or data errors that require further investigation are identified.
2.Association rule learning- This is also called dependency modeling which searches for relationships between variables. Also known as market basket analysis.
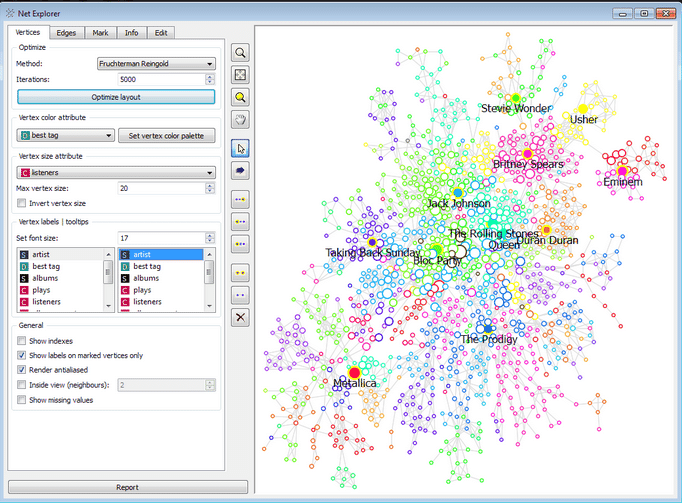
3.Clustering – Clustering is the task of discovering groups and structures in the data that are in some way or other similar without using known structures in the data.
4.Classification- Classification is the task of generalizing known structure to apply to new data.
5.Regression- Regression is the task with an objective to find a function which models the data with the least error.
6.Summarization- Summarization tasks provides a more compact representation of the data set, including visualization and report generation.
Data Mining Software
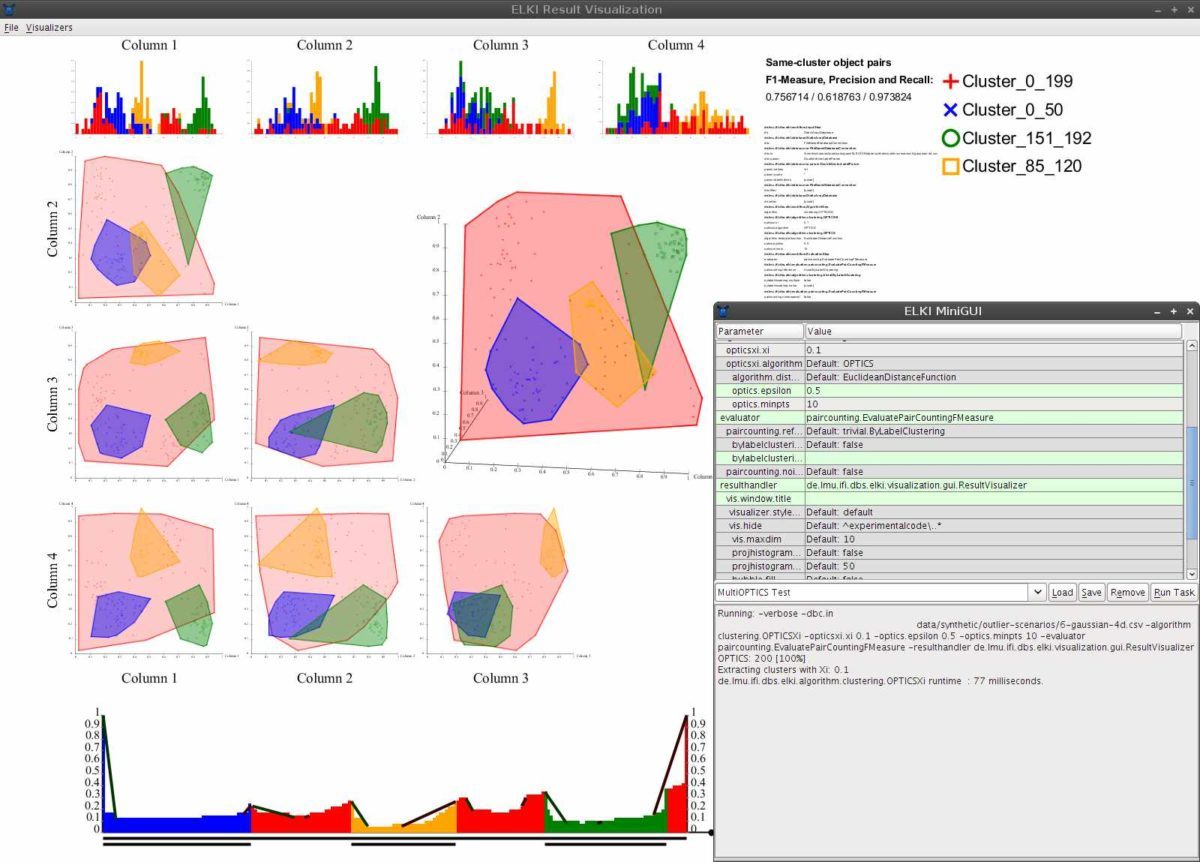
Orange Data mining, Anaconda, R Software Environment, Scikit-learn, Weka Data Mining, Shogun, DataMelt, Natural Language Toolkit, Apache Mahout, GNU Octave, GraphLab Create, ELKI, Apache UIMA, KNIME Analytics Platform Community, TANAGRA, Rattle GUI, CMSR Data Miner, OpenNN, Dataiku DSS Community, DataPreparator, LIBLINEAR, Chemicalize.org, Vowpal Wabbit, mlpy, Dlib, CLUTO, TraMineR, ROSETTA, Pandas, Fityk, KEEL, ADaMSoft, Sentic API, ML-Flex, Databionic ESOM, MALLET, streamDM, ADaM, MiningMart, Modular toolkit for Data Processing, Jubatus, LIBSVM, Arcadia Data Instant are some of the top free data mining software.
Orange Data mining, Anaconda, R Software Environment, Scikit-learn, Weka Data Mining, Shogun, Tableau Public, DataMelt, Microsoft R, Trifacta, SciPy, ELKI, KNIME Analytics Platform Community, Scilab, TANAGRA, Dataiku DSS Community, DataPreparator, ITALASSI, HP Vertica Advanced Analytics, Google Fusion Tables, NodeXL, Fluentd, Displayr, NumPy, OpenRefine, Julia, Massive Online Analysis, DataWrangler, EasyReg, Matplotlib, Ipython, SymPy, FreeMat, jMatLab, PAW, ILNumerics, ROOT, NetworkX, Arcadia Data Instant, SIGVIEW, Gephi are some of the free or open source top software for data analysis.
Data Mining is the computational process of discovering patterns, trends and behaviors, in large data sets using artificial intelligence, machine learning, statistics, and database systems. The overall goal of the data mining process is to extract information from a data set and transform it into an understandable structure for further use.
What are the tasks in Data Mining?
The tasks in data mining are either automatic or semi automatic analysis of large volume of data which are extracted to check for previously unknown interesting patterns. These are cluster analysis, anomaly detection on unusual records and dependencies check using the association rule mining. This usually involves using database techniques such as spatial indices.















By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.