Sign in to see all reviews and comparisons. It's Free!
By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.
Weka is a collection of machine learning algorithms for data mining tasks. Weka features include machine learning, data mining, preprocessing, classification, regression, clustering, association rules, attribute selection, experiments, workflow and visualization.
Category
Datamining Software
Features
• Data Pre-Processing • Data Classification • Data Regression • Data Clustering • Data Association rules • Data Visualization
License
Open Source Software
Price
Free
Pricing
Subscription
Free Trial
Available
Users Size
Small (<50 employees), Medium (50 to 1000 Enterprise (>1001 employees)
• Data Pre-Processing • Data Classification • Data Regression • Data Clustering • Data Association rules • Data Visualization
What are the benefits?
•Portable •Free to use •Easy to use •Adapted to creating new ways to machine learning designs •Contains tools with multiple uses •Free online courses available •Highly educated, skilled and committed professors. •Extremely resourceful books and publications available. •Latest trends in artificial intelligence
PAT Rating™
Editor Rating
Aggregated User Rating
Rate Here
Ease of use
9.1
6.3
Features & Functionality
9.2
6.4
Advanced Features
9.2
6.5
Integration
9.0
6.8
Performance
9.1
6.3
Customer Support
9.0
7.5
Implementation
7.2
Renew & Recommend
7.1
Bottom Line
Weka is a collection of machine learning algorithms for data mining tasks. Weka features include machine learning, data mining, preprocessing, classification, regression, clustering, association rules, attribute selection, experiments, workflow and visualization. Weka is written in Java, developed at the University of Waikato, New Zealand.
9.1
Editor Rating
6.5
Aggregated User Rating
50 ratings
You have rated this
Weka is a collection of machine learning algorithms for data mining tasks. The algorithms can either be applied directly to a dataset or called from your own Java code.
Weka features include machine learning, data mining, preprocessing, classification, regression, clustering, association rules, attribute selection, experiments, workflow and visualization. Weka is written in Java, developed at the University of Waikato, New Zealand.
All of Weka's techniques are predicated on the assumption that the data is available as a single flat file or relation, where each data point is described by a fixed number of attributes Weka provides access to SQL databases using Java Database Connectivity and can process the result returned by a database query. It is not capable of multi-relational data mining.
Weka
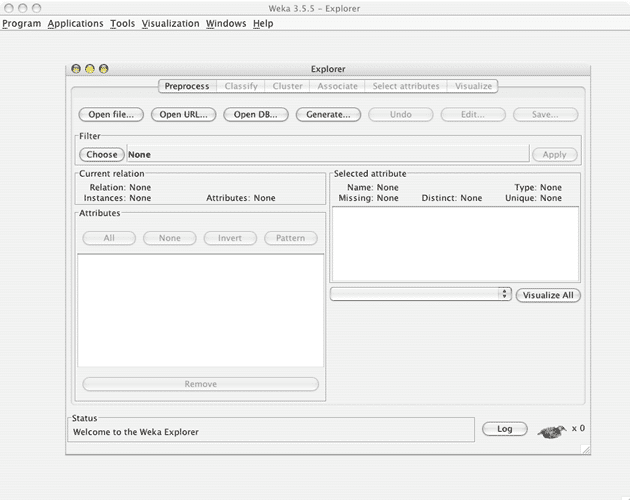
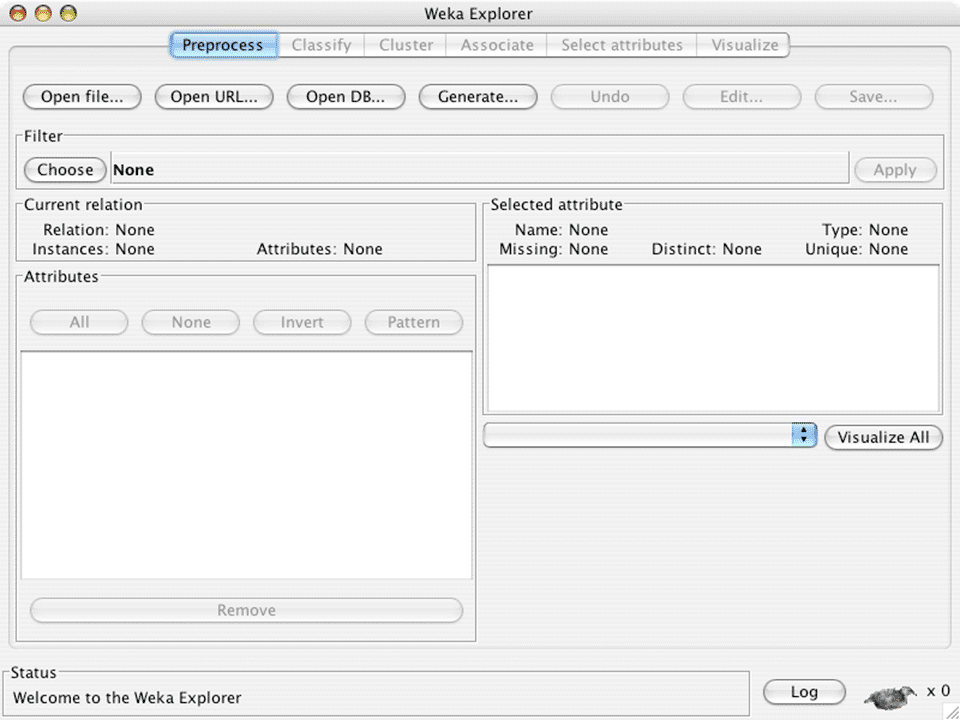
Weka's main user interface is the Explorer, the same functionality also can be accessed through the component-based Knowledge Flow interface and from the command line. There is also the Experimenter, which allows the systematic comparison of the predictive performance of Weka's machine learning algorithms on a collection of datasets. The Explorer interface features several panels providing access to the main components of the workbench such as preprocess panel which facilities for importing data, classify panel enables the user to apply classification and regression algorithms, associate panel provides access to association rule learners,cluster panel gives access to the clustering techniques, select attributes panel provides algorithms for identifying the most predictive attributes in a dataset, and visualize panel shows a scatter plot matrix.
Weka Explorer
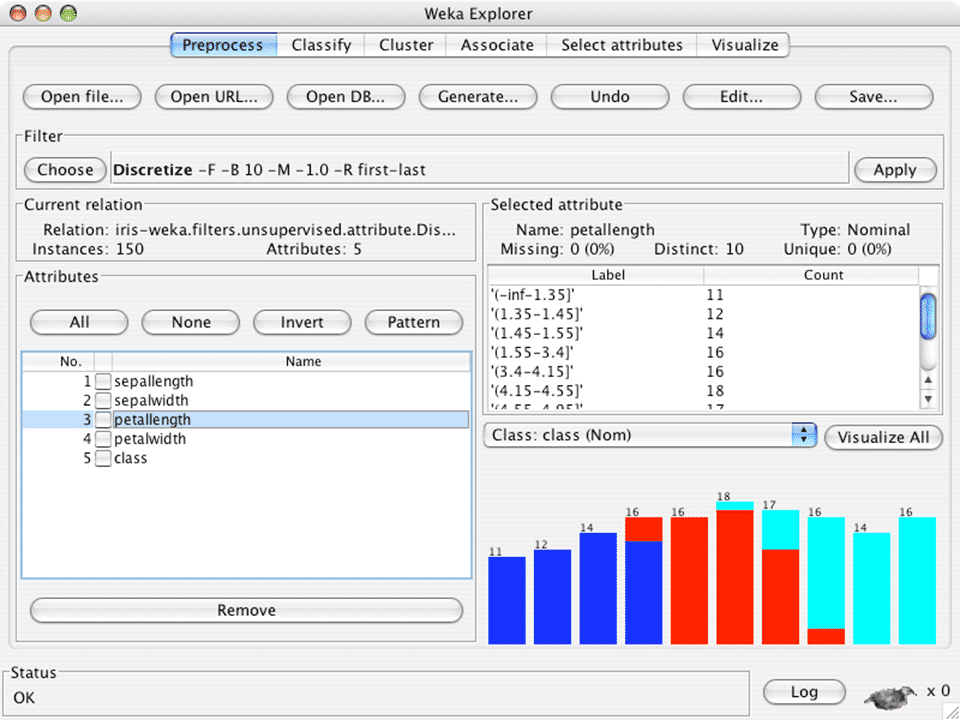
Weka provides comprehensive set of data pre-processing tools, learning algorithms and evaluation methods, graphical user interfaces and an environment for comparing learning algorithms. The data can be imported from a file in various formats such as ARFF, CSV, C4.5, binary. Data can also be read from a URL or from an SQL database (using JDBC). Pre-processing tools in WEKA are called “filters” and there are filters available for Discretization, normalization, resampling, attribute selection, transforming and combining attributes.
Weka Explorer
The implemented learning schemes are decision trees and lists, instance-based classifiers, support vector machines, multi-layer perceptrons, logistic regression, Bayes’ nets. The meta classifiers included are bagging, boosting, stacking, error-correcting output codes, locally weighted learning. The implemented schemes are k-Means, EM, Cobweb, X-means, FarthestFirst. The Clusters can be visualized and compared to “true” clusters . Apriori can compute all rules that have a given minimum support and exceed a given confidence. In Weka, data sources, classifiers, etc. are beans and can be connected graphically.
Weka also provides massive open online courses (MOOCs), books and other publications to teach implementations of algorithms and other machine learning techniques. Courses are taught by highly educated and seasoned lecturers who are also very committed to making students understand and be able to apply machine learning techniques.
Company size
Medium (50 to 1000)
User Role
IT Support
User Industry
Financial services
Rating
Ease of use8.4
Waikato Environment for Knowledge Analysis (Weka) is a free machine learning software, licensed under the GNU General Public License. It is written in Java, hence can run on any modern computing platform, hence very portable, and provides access to SQL databases.
Features & Functionality7.9
Advanced Features8.4
Integration7.8
Performance8.6
Training 7.7
Customer Support7.4
Implementation8.1
Renew & Recommend8.1
ADDITIONAL INFORMATION Weka is designed to carry out data analysis and predictive modeling. With graphical user interfaces which include Explore and Experimenter, it is quite easy to use. The tasks that Weka can perform include: preprocessing of data, data mining, machine learning, association rules, clustering, classification, regression, association rules, attribute selection, experiments, workflow, visualization and selection of features. Weka is also used for educational purposes.


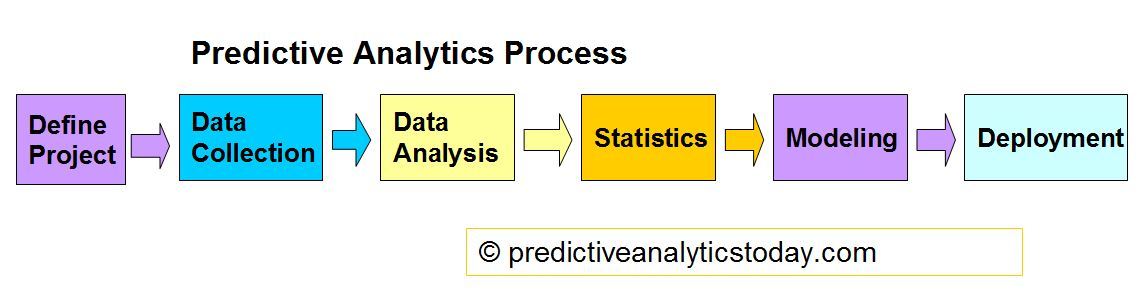








Data analysis and predictive modeling
Weka also provides massive open online courses (MOOCs), books and other publications to teach implementations of algorithms and other machine learning techniques. Courses are taught by highly educated and seasoned lecturers who are also very committed to making students understand and be able to apply machine learning techniques.
Medium (50 to 1000)
IT Support
Financial services
Waikato Environment for Knowledge Analysis (Weka) is a free machine learning software, licensed under the GNU General Public License. It is written in Java, hence can run on any modern computing platform, hence very portable, and provides access to SQL databases.
ADDITIONAL INFORMATION
Weka is designed to carry out data analysis and predictive modeling. With graphical user interfaces which include Explore and Experimenter, it is quite easy to use. The tasks that Weka can perform include: preprocessing of data, data mining, machine learning, association rules, clustering, classification, regression, association rules, attribute selection, experiments, workflow, visualization and selection of features. Weka is also used for educational purposes.