Sign in to see all reviews and comparisons. It's Free!
By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.
Bigdata
Now Reading
Waterline Data Self Service for the Hadoop data lake
Waterline Data Self Service for the Hadoop data lake
Waterline Data Self Service for the Hadoop data lake : Waterline Data Science is a Big Data software company, which solves the challenges of data self-service for the Hadoop data lake. It's easy to get data into Hadoop, but it's not easy to get it out in a self-service manner and derive business value from it. Waterline helps business to find data you need via self-service for Hadoop easily. Companies are deploying Hadoop “data lakes” to provide unprecedented access to data for data science and analytics to uncover new business insight. However, Hadoop’s advantages of frictionless ingest, flexible schema on read, coupled with the lack of data governance, present problems for users trying to find and understand the data. Waterline Data Inventory addresses these problems by building a complete inventory of data assets in Hadoop and by opening access to Hadoop data through data self-service. As a result, data scientists can be more productive, business analysts can easily augment reporting and BI with Hadoop data without coding, and data governance teams can start controlling Hadoop data.
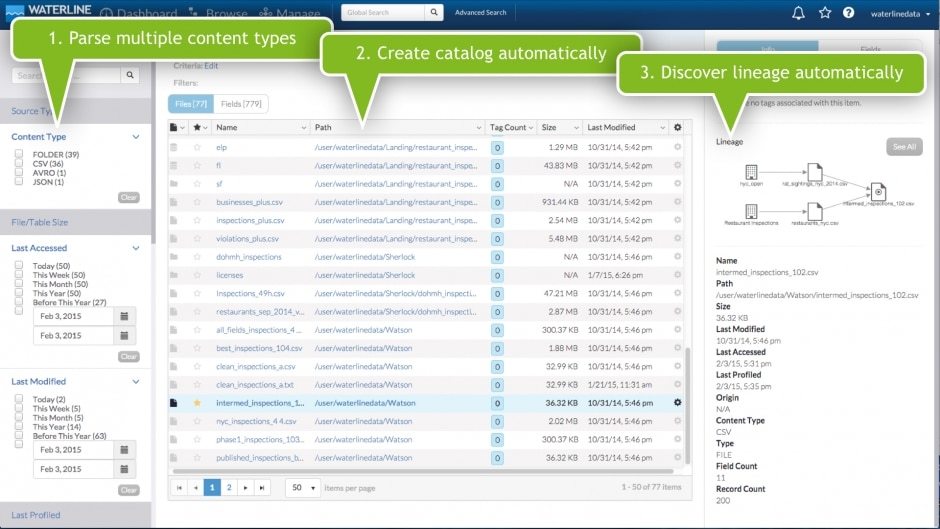
Waterline Data is an automated data discovery platform that helps data architects inventory all data in Hadoop automatically at scale, and provision data to business users securely. Waterline helps data engineers, data scientists, and business analysts to find the best-suited and most trusted data for data analysis automatically without having to explore every file manually. It helps data stewards discover lineage and business metadata automatically, as well as manage metadata.
Features include automated profiling, automated discovery and self service including format discovery, profiling, lineage discovery, sensitive data discovery, tag propagation, multi-faceted metadata search and hive table creation.
Waterline automatically discovers Hadoop file formats and detects schema changes and profiles data in the cluster and uses algorithms to compute detailed properties, and notifies the administrators of changes. It discovers file lineage automatically, and allows users and auditors to view and drill into the lineage information and identifies sensitive data throughout Hadoop clusters as a part of profiling with minimal additional overhead. Waterline recognizes similar content across files based on user tagging and propagates tags to similar fields automatically. Waterline infers facets from both data and metadata properties, and lets users create custom facets and allows users to create a Hive table with a click of a button and use it with a BI or visualization tool.
According to Alex Gorelik, Waterline Data Science founder and CEO, “A major complaint with Hadoop is that once you’ve loaded the data, extracting value is like finding a needle in a stack of needles. Waterline Data Inventory lets business users find the best needle in the stack of needles, without having to write code, and without having to wrangle the entire stack. That's our secret sauce, and key to delivering faster time to value and broad Hadoop adoption."










By clicking Sign In with Social Media, you agree to let PAT RESEARCH store, use and/or disclose your Social Media profile and email address in accordance with the PAT RESEARCH Privacy Policy and agree to the Terms of Use.